A convenience sample is simply any list, panel, or source of potential respondents. At Researchscape, we do lots of surveys of convenience samples. Because, of course, they’re convenient.
Also, cheap. We use house lists of emails of prospects, customers, and lapsed customers – no cost for these, with the caveat they present a skewed view of the universe, if used to generalize outside the list (as they frequently are used). We also use a wide range of panel companies, from qSample to Instantly to SSI and more, depending on the target audience.
While probability samples are more accurate, they are expensive and often impractical when targeting narrow populations: IT managers with on-site servers, Alzheimer caregivers whose loved-ones take a specific drug, iPhone 6 Plus users, etc.
Greg’s post yesterday on recent TrueSample research on research prompted me to review their entire presentation. One of their charts makes a point I often emphasize when talking about sampling: the answers vary widely, as with their estimate of the percentage of U.S. adults who are smokers across all 8 panel sources. The estimates ranged from 11% to 39%, while the CDC estimates that 18% of U.S. adults are smokers.
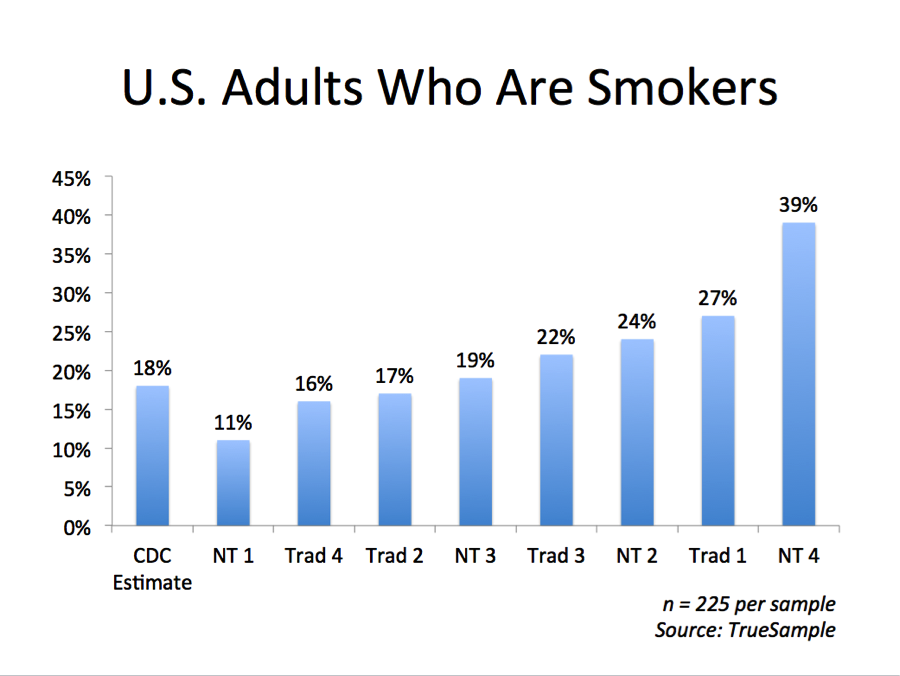
If these were probability samples, the margin of error would by 7% (sample size: 225 responses per source). Six of the eight sources fall within that margin of error, but two are way off. If these were probability samples, only one out of 20 should be way off. If we aggregated the results, our estimate of U.S. smoking would be 22%, also outside the margin of error (2% for 1,800 responses).
How do I talk about the uncertainty introduced by using convenience panels? Here’s an excerpt from my methodology page. I’d love your comments on it.
- As this was not a probability-based sample, calculating the theoretical margin of sampling error is not applicable. However, as with probability surveys, it is important to keep in mind that results are estimates and typically vary within a narrow range around the actual value that would be calculated by interviewing everyone in a population. Again, as with probability surveys, and more frequently than probability surveys, on occasion the results from a particular question will be completely outside a typical interval of error.
- There are many types of survey error that can limit the ability to generalize to a population. Throughout the research process, Researchscape followed a Total Survey Error approach designed to minimize error at each stage. Researchscape is confident that the information gathered from this survey can be used to make important business decisions related to the launch of this product concept.
Why do I use so many different panels? Each has strengths and weaknesses. One panel I frequently use for B2B work produces lower quality verbatim responses for concept testing, for instance, so I don’t use them for that application. As the chart above shows, representativeness of a sample source can vary widely. When taking on a new panel partner, it is always wise to read their ESOMAR 28, a 28-question FAQ that provides a sense for the best practices and processes they employ when managing their panel.
I have the highest confidence in my survey results when they are based on a probability sample. For e-commerce companies, we’re often able to do a random sample of all customers. For most businesses, though, we have to make do with imperfect sources.
However inconvenient that may be.
Author Notes:
Jeffrey Henning
